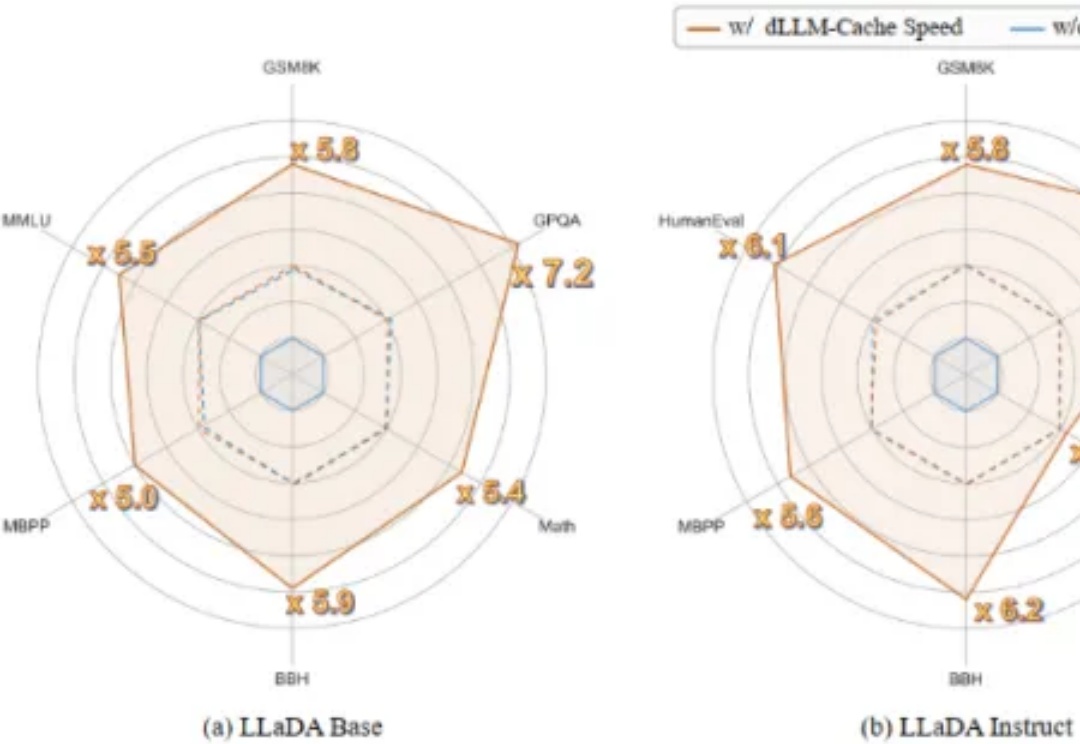
扩散语言模型九倍推理加速!上海交大:KV Cache并非自回归模型的专属技巧
扩散语言模型九倍推理加速!上海交大:KV Cache并非自回归模型的专属技巧首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
来自主题: AI技术研报
11769 点击 2025-05-27 16:22
 搜索
搜索
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
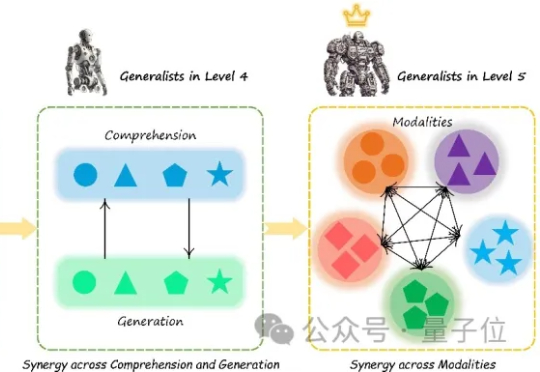
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。
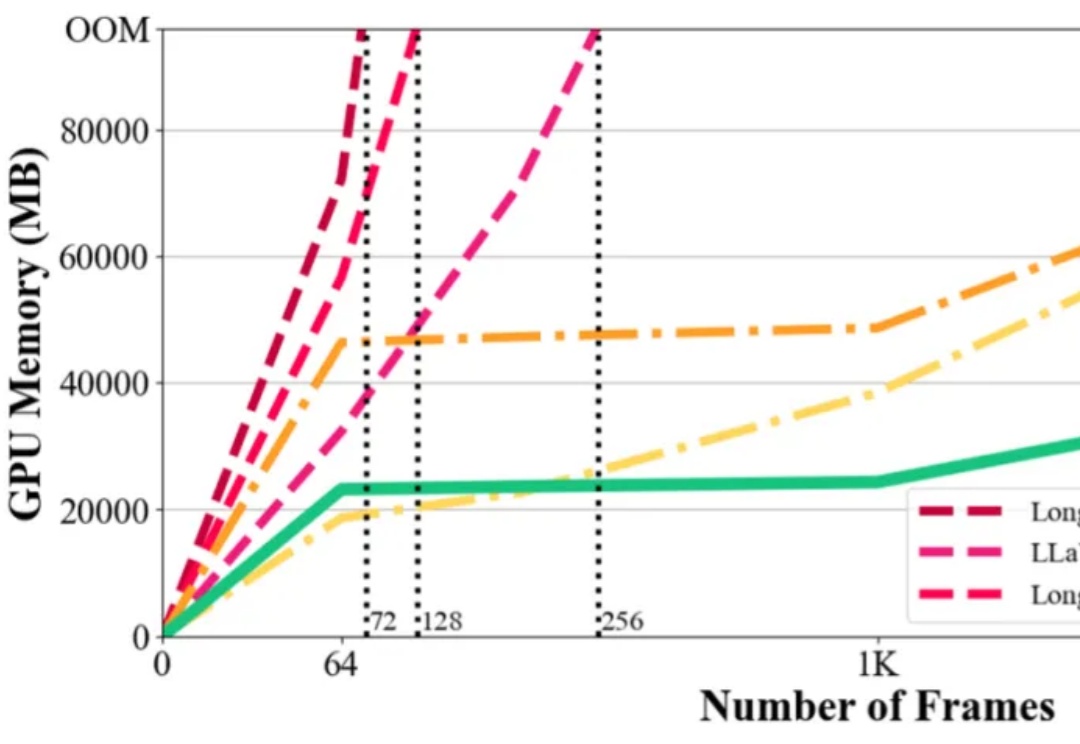
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。

怎么老是你???(How old are you)尤其是最近Meta FAIR研究员朱泽园分享了他们《Physics of Language Models》项目的系列新进展后,有网友发现,其中提到的3-token因果卷积相关内容,沙哥等又早在三年前就有相关研究。这是最近网友不断对着Transformer八子之一的Noam Shazeer(为方便阅读,我们称他为沙哥)发出的灵魂疑问。
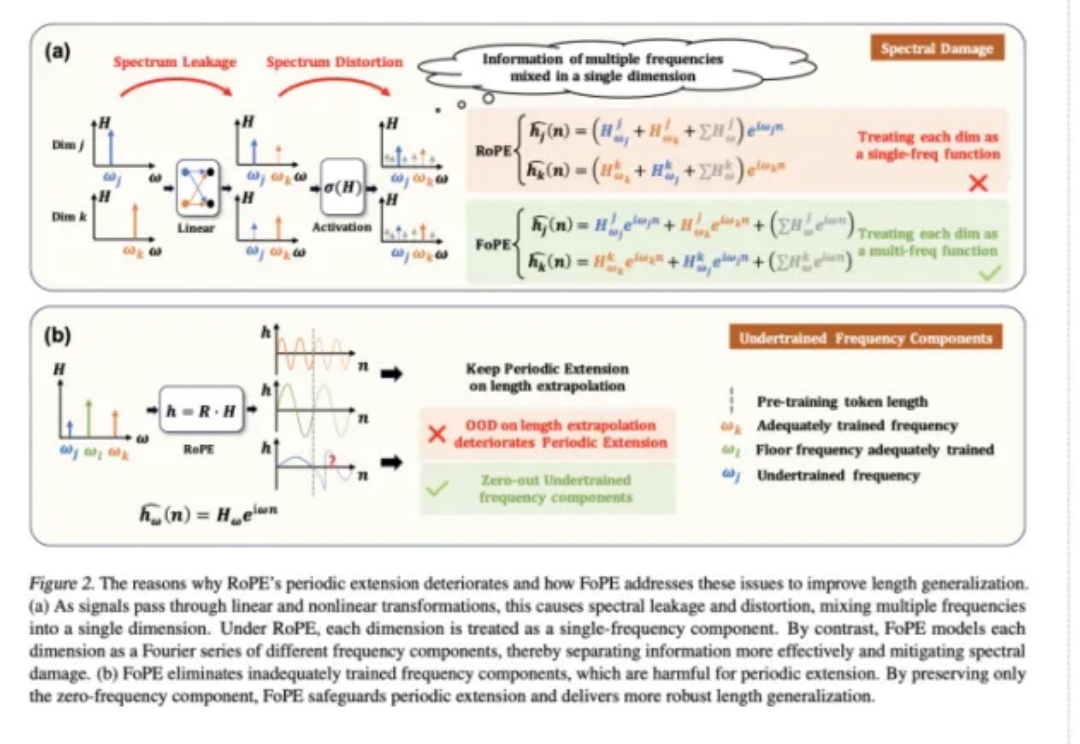
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?
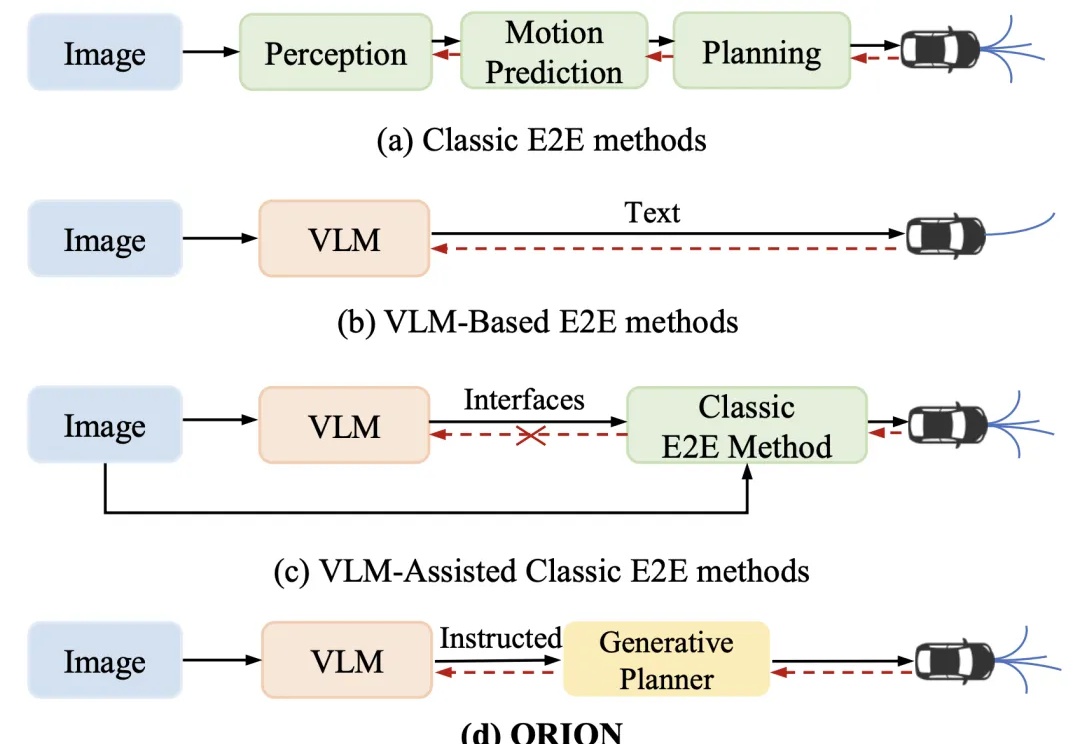
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
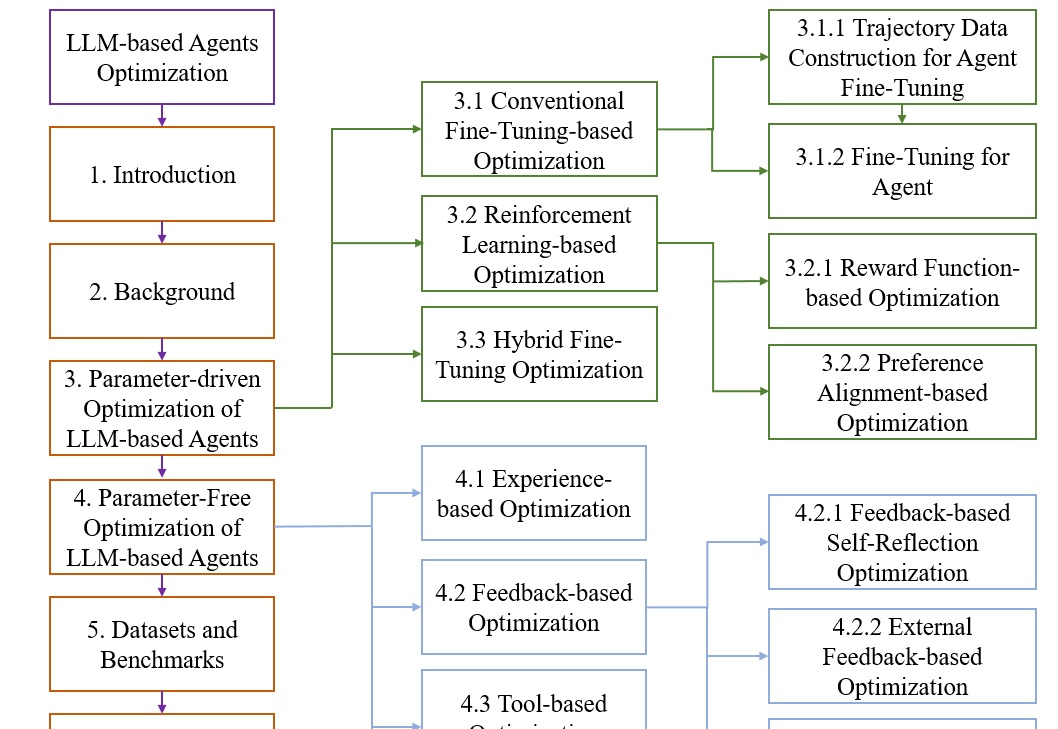
本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。
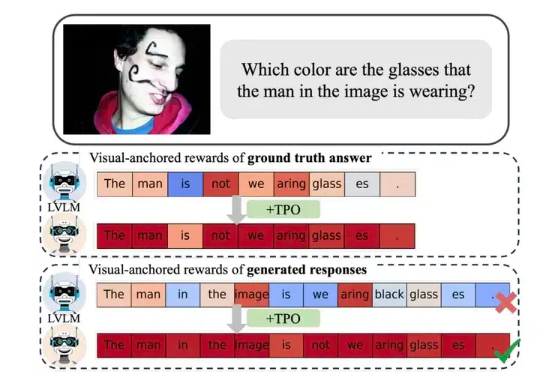
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。